Inhalt
- Anhang
- Cypher-Dokumentation
- Datenbank löschen
- Absicherung der Datenbank
- Datenbank exportieren, importieren und migrieren
- Indexe erstellen falls vorhanden
- Explorative Datenanalyse oder “Was ist in der Datenbank?”
- Weitere Labels für einen Knoten
- Aus Property weitere Kanten erstellen
- CSV-Feld enthält mehrere Werte
- Reguläre Ausdrücke
- Iso-Zeit- und Datumsangaben in neo4j-Datumsformat umrechnen
- Geokoordinaten in neo4j
- Vorkommende Wörter in einer Textproperty zu einer Textkette machen
- Vorkommende Wörter in einer Textproperty zählen
MERGEschlägt fehl da eine Property NULL ist- Der
WITH-Befehl - Export einer Graphdatenbank in ein cypher-file
- Export eines Subgraphen mit apoc.export.cypher.query
- Knoten hat bestimmte Kante nicht
- Shortest Path hat bestimmte Kanten nicht
- Häufigkeit von Wortketten
- Liste von Briefknoten nach Datum verketten
- Alle Indexe in einer Datenbank löschen
- Die Apoc-Bibliothek
- apoc.xml.import
- (apoc.load.json)
- (json in neo4j laden - der foreach-trick von Michael Hunger)
Anhang
In diesem Kapitel werden Tipps und Tricks rund um typische Herausforderungen bei der Verwendung von Graphdatenbanken in den digitalen Geisteswissenschaften vorgestellt. Die Hinweise stammen oft von meinem Kollegen Stefan Armbruster von neo4j, dem an dieser Stelle nochmal herzlich für seine Unterstützung gedankt sei.
Cypher-Dokumentation
Die Dokumentation von Cypher findet sich auf den Seiten von neo4j: https://neo4j.com/docs/developer-manual/current/
Datenbank löschen
Vorab hier der Befehl, mit dem eine neo4j-Datenbank geleert werden kann.
Kleine Datenbanken
MATCH (n) DETACH DELETE n;
Große Datenbanken
Bei großen Datenbanken funktioniert der o.a. Befehl meist nicht. Daher kann dieser Befehl genutzt werden, für den aber die APOC-Bibliothek installiert sein muss.
CALL apoc.periodic.iterate('MATCH (n) RETURN n', 'DETACH DELETE n', {batchSize:1000});
CALL apoc.schema.assert({},{},true) YIELD label, key
RETURN *;
oder ohne apoc:
:auto
MATCH (n)
WITH n
CALL {
WITH n
DETACH DELETE n}
IN TRANSACTIONS OF 1000 ROWS
RETURN count(*);
Absicherung der Datenbank
Die offizielle Dokumentation findet sich hier:
https://neo4j.com/docs/operations-manual/current/security/ssl-framework/
Einrichtung der Zertifikate
Zunächst muss ein Zertifikat beantragt werden. Anschließend müssen im Ordner /var/lib/neo4j/certificates die Ordner bolt und https erstellt werden. Im Ordner bolt muss noch der Unterordner truted erstellt werden. Das Zertifikat muss unter der Bezeichnung public.crt in die Ordner bolt, https und trusted kopiert werden. Die Schlüsseldatei muss unter der Bezeichnung private.key in die Ordner bolt und https kopiert werden.
In der Konfigurationsdatei /etc/neo4j/neo4j.conf muss die Verschlüsselung aktiviert werden.
Um nur noch verschlüsselte Verbindungen zuzulassen muss noch folgendes eingetragen werden:
dbms.connector.bolt.tls_level=REQUIRED
Zugriff über cypher-shell
Damit cypher-shell bei abgesicherter Datenbank funktioniert muss zunächst das Zertifikat importiert werden (Beispiel für debian):
sudo keytool -importcert -alias neo4jcert -cacerts -file /var/lib/neo4j/certificates/bolt/public.crt
Das Passwort ist changeit
Der Zugriff funktioniert dann mit:
cypher-shell -a sozinianer.mni.thm.de --encryption true
ACHTUNG: Als Serveradresse darf nicht die IP-Adresse angegeben werden sondern die beim Zertifikat hinterlegte Servername.
Passwort zurücksetzen oder ändern
Zunächst muss in neo4j.conf die Authentifizierung abgeschaltet werden. Die Stelle lautet:
# Whether requests to Neo4j are authenticated.
# To disable authentication, uncomment this line
dbms.security.auth_enabled=true
ändern zu
# Whether requests to Neo4j are authenticated.
# To disable authentication, uncomment this line
dbms.security.auth_enabled=false
Dann die DB neu starten und ohne Passwort einloggen.
Anschließend in die system-DB wechseln:
:use system
und das Passwort ändern:
ALTER USER neo4j SET PASSWORD 'mynewpassword'
Anschließend die Authentifizierung wieder einschalten und die DB neu starten.
Datenbank exportieren, importieren und migrieren
Aktuelle Informationen zu Import und Export finden sich unter https://neo4j.com/docs/operations-manual/current/backup-restore/
Datenbank exportieren über dump
Bei der Community Edition muss zunächst Neo4j gestoppt werden. Unter Debian lautet das entsprechende Kommando:
service neo4j stop
Anschließend kann der Datenbankdump erstellt werden:
neo4j-admin database dump
Das Dumpfile neo4j.dump findet sich dann im Ordner import. Nun kann die Datenbank wieder gestartet werden:
service neo4j start
Datenbank importieren
In neo4j.conf upgrade der DB erlauben:
Enable this to be able to upgrade a store from an older version.
dbms.allow_upgrade=true
Als Nutzer neo4j ausführen:
// Community Edition
linux-shell: neo4j-admin database load --from-path=/full-path/data/dumps neo4j --overwrite-destination=true
// Enterprise Edition noch zusätzlich die Datenbank stoppen, importieren und anschließend wieder starten
cypher-shell: :use system
cypher-shell: stop database hildegard;
linux-shell: neo4j-admin load --from import/neo4j.dump --force --database hildegard
cypher-shell: start database hildegard;
Datenbank importieren über dump für neo4j
Die Datei neo4j.dump muss im Verzeichnis data/dumps/ abgelegt werden. Anschließend:
bin/neo4j-admin database load --overwrite-destination=true neo4j
Datenbankimport mit Neo4j auf docker
Weitere Hinweise zum Import von Datenbanken für Neo4j auf docker finden sich unter https://github.com/THM-Graphs/knowledgebase/blob/main/cypher%20gems/using%20neo4j-admin%20dump%20and%20load.md
Datenbank von neo4j 4.4 auf neo4j 5.x migrieren
Die Migration von neo4j 4.4 auf die Version 5.x kann über neo4j Desktop erfolgen. Zunächst muss ein Dump der neo4j 4.4 Datenbank erstellt werden. Anschließend wir in neo4j Desktop eine Datebank neo4j 5.x erstellt. Im Datenbankverzeichnis wird ein Order data/dumps erstellt, in den die Datei neo4j.dump hineinkopiert wird. Der Befehl für die Migration lautet dann:
bin/neo4j-admin database migrate neo4j
Siehe auch https://neo4j.com/docs/upgrade-migration-guide/current/version-5/migration/migrate-databases/
Daten exportieren als cypher Statement (Quelle)
In neo4j.conf Import und Export für apoc erlauben:
apoc.export.file.enabled=true
apoc.import.file.enabled=true
Anschließend die gesamte Datenbank in cypher exportieren
// Export der gesamten Datenbank
CALL apoc.export.cypher.all('export.cypher',{format:'cypher-shell'})
// Export eine Subgraphen mit Knoten und Kanten inkl. Indexes als cypher Statements
MATCH path = (p1:Person)-[r:KNOWS]->(p2:Person)
WITH collect(p1)+collect(p2) as export_nodes, collect(r) as export_rels
CALL apoc.export.cypher.data(export_nodes,export_rels,'export.cypher',{format:'cypher-shell'})
YIELD file, source, format, nodes, relationships, properties, time
RETURN nodes, relationships, time;
// Export eines Subgraphen incl. Indexe
...
CALL apoc.graph.fromPaths([paths],'export_graph',{}) YIELD graph
CALL apoc.export.cypher.graph(graph,'export.cypher',{format:'cypher-shell'}) YIELD time
RETURN time;
// Export von Knoten und Kanten eines gegebenen cypher Queries inkl. Indexe
CALL apoc.export.cypher.query(
'MATCH (p1:Person)-[r:KNOWS]->(p2:Person) RETURN *',
'export.cypher',{format:'cypher-shell'});
Die Datei export.cypher befindet sich nach dem Export im Verzeichnis import der Datenbank
Datenbank importieren über cypher-shell
cat export.cypher | ./bin/cypher-shell -u neo4j -p password
cypher-shell -u neo4j -p password < export.cypher
Indexe erstellen falls vorhanden
Seit Neo4j 4 gibt es eine Fehlermeldung, wenn man versucht einen Index zu erzeugen, der schon vorhanden ist, was bei Skripten ärgerlich sein kann. Mit folgendem Befehl kann man einen Index nur dann erstellen, wenn er noch nicht vorhanden ist.
CREATE INDEX IF NOT EXISTS FOR (n:Person) ON (n.genID);
Tipp: Wenn es schon Befehle zur Indexerstellung gibt wir z.B.
CREATE INDEX ON :IndexPerson(registerid);
kann man diese durch Suchen und Ersetzen in der folgenen Reihenfolge updaten:
(
) ON (n.
CREATE INDEX ON :
CREATE INDEX IF NOT EXISTS FOR (n:
Das Ergebnis sieht dann so aus:
CREATE INDEX IF NOT EXISTS FOR (n:Person) ON (n.registerid);
Explorative Datenanalyse oder “Was ist in der Datenbank?”
Schema der Graphdatenbank
Mit diesem Befehl lässt sich das Schema des Graphmodells anzeigen.
CALL db.schema.visualization();
Für den Befehl muss die APOC-Bibliothek installiert sein.
Welche und jeweils wieviele Knoten enthält die Datenbank
Mit den in diesem Abschnitt vorgestellten Queries lassen sich Graphen explorativ erfassen. Mit dem folgenden Query findet man alle im Graph vorkommenden Typen von Knoten und die jeweiligen Häufigkeiten.
CALL db.labels()
YIELD label
CALL apoc.cypher.run("MATCH (:`"+label+"`)
RETURN count(*) as count", null)
YIELD value
RETURN label, value.count as count
ORDER BY label;
Welche Verknüpfungen gibt es in der Datenbank und wie häufig sind sie
Der nächste Query führt die gleiche Untersuchung für die in der Graphdatenbank vorhanden Kantentypen durch.
CALL db.relationshipTypes()
YIELD relationshipType
CALL apoc.cypher.run("MATCH ()-[:" + `relationshipType` + "]->()
RETURN count(*) as count", null)
YIELD value
RETURN relationshipType, value.count AS count
ORDER BY relationshipType;
Mit diesen Queries lässt sich bei unbekannten Graphdatenbanken ein erster Überblick zur statistischen Verteilung von Knoten- und Kantentypen erstellen.
Mit dem folgenden Query werden alle Typen von Knoten und deren jeweilige Häufigkeit aufgelistet.
CALL db.labels()
YIELD label
CALL apoc.cypher.run("MATCH (:`"+label+"`)
RETURN count(*) as count", null)
YIELD value
RETURN label, value.count as count
ORDER BY count DESC;
CALL db.relationshipTypes()
YIELD relationshipType
CALL apoc.cypher.run("MATCH ()-[:`" + relationshipType + "`]->()
RETURN count(*) as count", null)
YIELD value
RETURN relationshipType, value.count AS count
ORDER BY count DESC;
Welche Knoten haben keine Kanten
MATCH (n)
WHERE size((n)--())=0
RETURN DISTINCT labels(n);
Weitere Labels für einen Knoten
Gegeben sind Knoten vom Typ IndexEntry, die in der Property type noch näher spezifiziert sind (z.B. Ort, Person, Sache etc.). Mit dem folgenden Query wird der Wert der Property type als zusätzliches Label angelegt.
MATCH (e:IndexEntry)
WHERE e.type IS NOT NULL
WITH e, e.type AS label
CALL apoc.create.addLabels(id(e), [label]) YIELD node
RETURN node;
Die Namen der Labels können auch selbst bestimmt werden.
MATCH (e:IndexEntry)
WHERE e.type = 'person'
WITH e
CALL apoc.create.addLabels(id(e), ['IndexPerson']) YIELD node
RETURN node;
MATCH (e:IndexEntry)
WHERE e.type = 'ereignis'
WITH eCALL apoc.create.addLabels(id(e), ['IndexEvent']) YIELD node
RETURN node;
MATCH (e:IndexEntry)
WHERE e.type = 'sache'
WITH e
CALL apoc.create.addLabels(id(e), ['IndexThing']) YIELD node
RETURN node;
MATCH (e:IndexEntry)
WHERE e.type = 'ort'
WITH e
CALL apoc.create.addLabels(id(e), ['IndexPlace']) YIELD node
RETURN node;
Aus Property weitere Kanten erstellen
Gegeben sind Kanten vom Typ APPEARS_IN wobei die Rolle der Entität in der Kanten-Property Role steht. Mit dem folgenden Query wird der Wert der Role-Property type als zusätzliches Kante angelegt.
MATCH (s:Regesta<-[r:APPEARS_IN]-(e:Entity)
WHERE r.role IS NOT NULL
CALL (s,r,e) {
CALL apoc.create.relationship(s, toUpper(r.role), {}, e) YIELD rel
DELETE r
} IN TRANSACTIONS OF 1000 ROWS;
CSV-Feld enthält mehrere Werte
Beim Import von Daten im CSV-Format in die Graphdatenbank kann es vorkommen, dass in einem CSV-Feld mehrere Werte zusammen stehen. In diesem Abschnitt wird erklärt, wie man diese Werte auseinandernehmen, einzeln im Rahmen des Imports nutzen kann.
In der Regel ist es von Vorteil, zunächst das CSV-Feld als eine Property zu importieren und in einem zweiten Schritt auseinanderzunehmen.
Angenommen wir haben Personen importiert, die in der Property abschluss eine kommaseparierte Liste von verschiedenen beruflichen Abschlüssen haben, wie z.B. Lehre, BA-Abschluss, MA-Abschluss, Promotion.
In der Property abschluss steht zum Beispiel:
lic. theol., mag. art., dr. theol., bacc. art., bacc. bibl. theol.
Für die Aufteilung der Einzelwerte kann die split-Funktion verwendet werden, die einen String jeweils an einem anzugebenden Schlüsselzeichen (hier das Komma) auftrennt. Der Befehl hierzu sieht wie folgt aus:
MATCH (p:Person)
FOREACH ( j in split(p.abschluss, ",") |
MERGE (t:Titel {name:trim(j)})
MERGE (t)<-[:ABSCHLUSS]-(p)
);
Der Query trennt die Liste von Abschlüssen jeweils beim Komma, erstellt mit dem MERGE-Befehl einen Knoten für den Abschluss (falls noch nicht vorhanden) und verlinkt diesen Knoten dann mit dem Personenknoten.
Zu beachten ist, dass die im CSV-Feld vorhandenen Begriffe konsistent benannt sein müssen.
Reguläre Ausdrücke
Reguläre Ausdrücke mit cypher
Im folgenden Beispiel werden die Properties startDate and endDate auf Korrektheit überprüft.
match (r:Regesta)
where not r.startDate =~ "[0-9]{4}-[0-1]{1}[0-9]{1}-[0-3]{1}[0-9]{1}" or not r.endDate =~ "[0-9]{4}-[0-1]{1}[0-9]{1}-[0-3]{1}[0-9]{1}"
return r.identifier, r.startDate, r.endDate
Damit können Tippfehler in den Datumsangaben gefunden werden (z.B. 0903-21-11).
Reguläre Ausdrücke mit apoc
Mit dem Befehl apoc.text.regexGroups ist es möglich, reguläre Ausrücke zum Auffinden und Ändern von Property-Werten zu nutzen.
Beispiel: Überlieferung des Regest RI III,2,3 n. 3:
Herim. Aug. 1051 (<link http://opac.regesta-imperii.de/lang_de/
kurztitelsuche_r.php?kurztitel=pertz,_hermann_von_reichenau>SS 5, 129</link>);
vgl. Wibert, V. Leonis IX. II, 7 (<link
http://opac.regesta-imperii.de/lang_de/kurztitelsuche_r.php?
kurztitel=watterich,_pontificum_romanorum_vitae>Watterich 1, 159</link>).
Mit dem folgenden Query werden in den Überlieferungsteilen der Regesten Kaiser Heinrichs IV. die Verlinkungen der Litereratur herausgesucht und für jeden Link per MERGE ein Knoten erzeugt. Anschließend werden die neu erstellen Knoten mit den jeweiligen Regesten über eine REFERENCES-Kante verbunden.
MATCH (reg:Regesta)
WHERE reg.archivalHistory CONTAINS "link"
UNWIND apoc.text.regexGroups(reg.archivalHistory, "<link (\\S+)>(\\S+)</link>") as link
MERGE (ref:Reference {url:link[1]}) ON CREATE SET ref.title=link[2]
MERGE (reg)-[:REFERENCES]->(ref);
Iso-Zeit- und Datumsangaben in neo4j-Datumsformat umrechnen
Wenn in neo4j Datumsangaben iso-konform im Format JJJJ-MM-TT (also Jahr-Monat-Tag) abgespeichert sind, behandelt Neo4j diese Angaben aber immer noch als String. Um Datumsberechnungen durchführen zu können, müssen die Strings in neo4j-interne Datumswerte umgerechnet werden. Der Cypher-Query am Beispiel der Regesta Imperii hierzu sieht wie folgt aus:
// Date in neo4j-Datumsformat umwandeln
MATCH (n:Regesta)
SET n.isoStartDate = date(n.startDate);
MATCH (n:Regesta)
SET n.isoEndDate = date(n.endDate);
MATCH (d:Date)
SET d.isoStartDate = date(d.startDate);
MATCH (d:Date)
SET d.isoEndDate = date(d.endDate);
Zunächst werden mit dem MATCH-Befehl alle Regestenknoten aufgerufen. Anschließend wird für jeden Regestenknoten aus der String-Property startDate die Datumsproperty isoStartDate berechnet und im Regestenknoten abgespeichert. Mit Hilfe der Property können dann Datumsangaben und Zeiträume abgefragt werden (Beispiel hierzu unten in der Auswertung).
Geokoordinaten in neo4j
In den Properties von Knoten können auch Geokoorinaten gespeichert und analysiert werden. Angenommen im Knoten (n) enthält die Property n.latitude die Angaben zum Breitengrad und die Property n.longitude die Angaben zum Längengrad. Dann kann mit dem folgenden Query die Property n.nLatLong erstellt werden, mit der dann Entfernungsberechnungen durchgeführt werden können:
// Property zur Entfernungsberechnung erstellen
MATCH (o:Ort)
SET o.nLatLong = point({latitude: tofloat(line.Latitude), longitude: tofloat(line.Longitude)});
RETURN *;
Beispiele zur Auswertung an Hand der Regesta Imperii finden Sie in dieser Präsentation auf dieser Folie.
Hier noch eine cypher-Beispiel zur Abfrage der Ausstellungsorte in den Regesten Kaiser Heinrichs IV. (Band RI III,2,3) mit der Datumseinschränkung 1.1.1085 bis 1.1.1090. Die Ausgabe ist für die direkte Übernahme in den Dariah-Geobrowser formatiert. Über r.identifier lässt sich der Regestenband und über isoStartDate und isoEndDate der Zeitraum anpassen.
MATCH (p)-[:PLACE_OF_ISSUE]-(r:Regesta)
WHERE p.latLong IS NOT NULL
AND r.identifier =~ 'RI III,2,3 .*'
AND r.isoStartDate > date('1085-01-01')
AND r.isoEndDate < date('1090-01-01')
RETURN p.normalizedGerman AS Name, p.normalizedGerman AS Address,
r.identifier AS Description, p.longitude AS Longitude, p.latitude AS Latitude, r.isoStartDate AS Timestamp
Geokoordinaten für den Dariah Geobrowser exportieren
// Geobrowser-Export
MATCH (p:Place)--(l:Letter)
RETURN p.label AS Name, p.label AS Address,
p.label AS Description, p.longitude AS Longitude, p.latitude AS Latitude, l.dateNorm AS Timestamp;
Vorkommende Wörter in einer Textproperty zu einer Textkette machen
MATCH (t:Text)
WITH t.Value as sentence, t.Name as b
WITH split(sentence," ") as words, b
FOREACH ( idx IN range(0,size(words)-2) |
MERGE (w1:Token {value:trim(words[idx])})
MERGE (w2:Token {value:trim(words[idx+1])})
CREATE (w1)-[r:NEXT {Briefnr:b}]->(w2));
In der folgenden Fassung werden die Briefnummern noch in den Kanten ergänzt
// Property as Array with one Relation
MATCH (t:Text)
WITH t.Value as sentence, t.Name as b
WITH split(sentence," ") as words, b
FOREACH ( idx IN range(0,size(words)-2) |
MERGE (w1:Token {value:trim(words[idx])})
MERGE (w2:Token {value:trim(words[idx+1])})
MERGE (w1)-[r:NEXT]->(w2)
ON CREATE SET r.list = b
ON MATCH SET r.list = r.list + ", " + b);
Vorkommende Wörter in einer Textproperty zählen
Werden Texte in der Property source eines Knotens l gespeichert, kann man sich mit folgendem Query die Häufigkeit der einzelnen Wörter anzeigen lassen.
match (l:Letter)
return apoc.coll.frequencies(
apoc.coll.flatten(
collect(
split(
apoc.text.regreplace(l.source, "[^a-zA-Z0-9ÄÖÜäöüß ]",""
),
" ")
)
);
In der folgenden Fassung wird die Liste noch nach Häufigkeit sortiert.
match (l:Letter)
with apoc.coll.frequencies(
apoc.coll.flatten(collect(
split(
apoc.text.regreplace(l.source, "[^a-zA-Z0-9ÄÖÜäöüß ]","")
, " ")
)
)
) as freq
unwind freq as x
return x.item, x.count order by x.count desc
MERGE schlägt fehl da eine Property NULL ist
Der MERGE-Befehl entspricht in der Syntax dem CREATE-Befehl, überprüft aber bei jedem Aufruf, ob der zu erstellende Knoten bereits in der Datenbank existiert. Bei dieser Überprüfung werden alle Propertys des Knoten verglichen. Falls also ein vorhandener Knoten eine Property nicht enthält, wird ein weiterer Knoten erstellt. Umgekehrt endet der MERGE-Befehl mit einer Fehlermeldung, wenn eine der zu prüfenden Propertys NULL ist.
Gerade beim Import von CSV-Daten leistet der MERGE-Befehl in der Regel sehr gute Dienste, da man mit ihm bereits beim Import einer Tabelle weitere Knotentypen anlegen und verlinken kann. Oft kommt es aber vor, dass man sich nicht sicher ist, ob eine entsprechende Property in allen Fällen existiert. Hier bietet es sich an, vor dem MERGE-Befehl mit einer WHERE-Clause die Existenz der Property zu überprüfen.
Im folgenden Beispiel importierten wir Personen aus einer CSV-Liste, bei denen pro Person jeweils eine ID, ein Name und manchmal ein Herkunftsort angegeben ist. Im ersten Schritt werden im CREATE-Statement die Personen erstellt und auch der Herkunftsort als Property angelegt, der aber auch NULL sein kann.
LOAD CSV WITH HEADERS FROM "file:///import.csv" AS line
CREATE (p:Person {pid:line.ID_Person, name:line.Name, herkunft:line.Herkunft});
Hinweise: Wenn der Import fehlschlägt kann das an der Formatierung der CSV-Datei liegen. Wenn die Daten aus Libreoffice exportiert wurden kann dies helfen:
sed -e 's/\\""/\\"/g' SBW-Register-Briefe.csv > SBW-Register-Briefe-fixed.csv
Im zweiten Schritt wird nun der LOAD CSV-Befehl nochmals ausgeführt und über die WHERE-Clause nur jene Fälle weiter bearbeitet, in denen die Property Herkunft nicht NULL ist. Nach der WHERE-Clause wird über den MATCH-Befehl zunächst der passende Personenknoten aufgerufen, anschließend per MERGE-Befehl der Ortsknoten erstellt (falls noch nicht vorhanden) und schließlich mit MERGE beide verknüpft.
LOAD CSV WITH HEADERS FROM "file:///import.csv" AS line
WHERE line.Herkunft IS NOT NULL
MATCH (p:Person {pid:line.ID_Person})
MERGE (o:Ort {ortsname:line.Herkunft})
MERGE (p)-[:HERKUNFT]->(o);
Der WITH-Befehl
Da Cypher eine deklarative und keine imperative Sprache ist, gibt es bei der Formulierung der Querys Einschränkungen.1 Hier hilft oft der WITH-Befehl weiter, mit dem sich die o.a. beiden Befehle auch in einem Query vereinen lassen:
LOAD CSV WITH HEADERS FROM "file:///import.csv" AS line
CREATE (p:Person {pid:line.ID_Person, name:line.Name, herkunft:line.Herkunft})
WITH line, p
WHERE line.Herkunft IS NOT NULL
MERGE (o:Ort {ortsname:line.Herkunft})
MERGE (p)-[:HERKUNFT]->(o);
Der LOAD CSV-Befehl lädt die CSV-Datei und gibt sie zeilenweise an den CREATE-Befehl weiter. Dieser erstellt den Personenknoten. Der folgende WITH-Befehl stellt quasi alles wieder auf Anfang und gibt an die nach ihm kommenden Befehle nur die Variablen line und p weiter.
Export einer Graphdatenbank in ein cypher-file
In Neo4j Desktop kann eine Graphdatenbank mit diesem Befehl exportiert werden: Dokumentation: https://neo4j.com/labs/apoc/4.1/export/cypher/#export-cypher-neo4j-browser
CALL apoc.export.cypher.all("all-plain.cypher", {
format: "plain",
useOptimizations: {type: "UNWIND_BATCH", unwindBatchSize: 20}
})
YIELD file, batches, source, format, nodes, relationships,
properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships,
properties, time, rows, batchSize;
Den Export findet man dann im Import-Ordner der Datenbank. Diese Datei kann in einen anderen Neo4j-Browser in die Eingabezeile gezogen und dann importiert werden.
Auch mit der cypher-shell kann der Export wieder importiert werden:
cypher-shell -u neo4j -p password < all-plain.cypher
Export eines Subgraphen mit apoc.export.cypher.query
Hier wird beschrieben, wie man einen Teil einer Graphdatenbank, einen sogenannten Sub-Graphen, exportieren und in eine neue Graphdatenbank importieren kann. Weitere Infos zum Befehl apoc.export.cypher.query finden Sie auf der Quelle dieser Seite.
Export des Subgraphen
// Export von Knoten und Kanten des cypher-Statements inkl. der Indexe als cypher-Statements in die genannte Datei
CALL apoc.export.cypher.query(
'MATCH (p1:Person)-[r:KNOWS]->(p2:Person) RETURN p1, r, p2',
'/tmp/export.cypher',{format:'cypher-shell'});
Zu beachten ist, dass beim RETURN-Befehl explizit p1, p2 und r erwähnt werden. Dies ergibt die Datei export.cypher im Verzeichnis /tmp. Der Inhalt dieser Datei kann als Text in die Befehlszeile des neo4j-Browsers einer leeren Graphdatenbank kopiert und ausgeführt werden. Damit wird dann aus Subgraph erstellt.
Import des Subgraphen in eine neue Datenbank über die cypher-Shell
Alternativ kann die exportierte Datei direkt über die cypher-Shell importiert werden:
cat /tmp/export.cypher | ./bin/cypher-shell -u neo4j -p password
Knoten hat bestimmte Kante nicht
Am Beispiel der Regesta-Imperii-Graphdatenbank der Regesten Kaiser Friedrichs III. werden mit dem folgenden Cypher-Query alle Regestenknoten ausgegeben, die keine PLACE_OF_ISSUE-Kante zu einem Place-Knoten haben:
MATCH (reg:Regesta)
WHERE NOT
(reg)-[:PLACE_OF_ISSUE]->(:Place)
RETURN reg;
Shortest Path hat bestimmte Kanten nicht
Am Beispiel der Fraktalität und Dynamik Graphdatenbank werden mit dem folgenden Cypher-Query die Kantentypen ‘BEGRABEN_IN’ und ‘VERSTORBEN_IN’ aus dem shortestPath p ausgeschlossen:
MATCH (n1:Person {pid: '3699' }),(n2:Person {pid: '3785' }), p = shortestPath((n1)-[*]-(n2))
WHERE NONE (r IN relationships(p) WHERE type(r)= 'BEGRABEN_IN')
AND NONE (r IN relationships(p) WHERE type(r)= 'VERSTORBEN_IN')
RETURN p
Häufigkeit von Wortketten
Am Beispiel des DTA-Imports von Berg Ostasien wird mit dem folgenden Query die Häufigkeit von Wortketten im Text ausgegeben:
MATCH p=(n1:Token)-[:NEXT_TOKEN]->(n2:Token)-[:NEXT_TOKEN]->(n3:Token)
WITH n1.text as text1, n2.text as text2, n3.text as text3, count(*) as count
WHERE count > 1 // evtl höherer Wert hier
RETURN text1, text2, text3, count ORDER BY count DESC LIMIT 10
Liste von Briefknoten nach Datum verketten
Gegeben sei eine Menge von Briefknoten, die das Absendedatum in der Property sendDate abgespeichert haben. Der folgende Query verkettet die Briefe in der Reihenfolge des Absendedatums mit NEXT_LETTER-Kanten.
MATCH (n:Brief)
WITH n ORDER BY n.sendDate
WITH collect(n) as briefe
CALL apoc.nodes.link(briefe, "NEXT_LETTER")
RETURN count(*)
Soll es sich nur um virtuelle Kanten handeln, können diese beispielhaft für diese GraphDB so erstellt werden:
MATCH (s:Person {gnd:'http://d-nb.info/gnd/118607626'})<-[:SENDER|:RECEIVER]-(b:Letter)-[:RECEIVER]->(e:Person)
WITH b, s, e ORDER BY b.sendDate ASC
WITH collect(distinct b) as briefe, collect(s) as p1, collect(e) as p2
UNWIND range(0,size(briefe)-2) AS i
RETURN briefe, collect( apoc.create.vRelationship(briefe[i], "NEXT_BRIEF", {}, briefe[i+1])), p1, p2;
Alle Indexe in einer Datenbank löschen
Mit dem folgenden Befehl lassen sich alle Indexe einer Datenbank auf einmal löschen.
CALL apoc.schema.assert({},{},true) YIELD label, key
RETURN *;
Die Apoc-Bibliothek
Die Funktionalitäten sind bei neo4j in verschiedene Bereiche aufgeteilt. Die Datenbank selbst bringt Grundfunktionalitäten mit. Um Industriestandards zu genügen haben diese Funktionen umfangreiche Tests und Prüfungen durchlaufen. Weiteregehende Funktionen sind in die sogenannte Apoc-Bibliothek ausgelagert, die zusätzlich installiert werden muss. Diese sogenannten user defined procedures sind benutzerdefinierte Implementierungen bestimmter Funktionen, die in Cypher selbst nicht so leicht ausgedrückt werden können. Diese Prozeduren sind in Java implementiert und können einfach in ihre neo4j-Instanz implementiert und dann direkt von Cypher aus aufgerufen werden.2
Die Apoc-Bibliothek besteht aus vielen Prozeduren, die bei verschiedenen Aufgaben in Bereichen wie Datenintegration, Graphenalgorithmen oder Datenkonvertierung helfen.
Installation in neo4j
Die Apoc-Bibliothek lässt sich unter http://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/%7Bapoc-release%7D herunterladen und muss in den plugin-Ordner der neo4j-Datenbank kopiert werden.
Installation unter neo4j-Desktop
In neo4j-Desktop kann die Apoc-Bibliothek jeweils pro Datenbank im Management-Bereich über den Reiter plugins per Mausklick installiert werden.
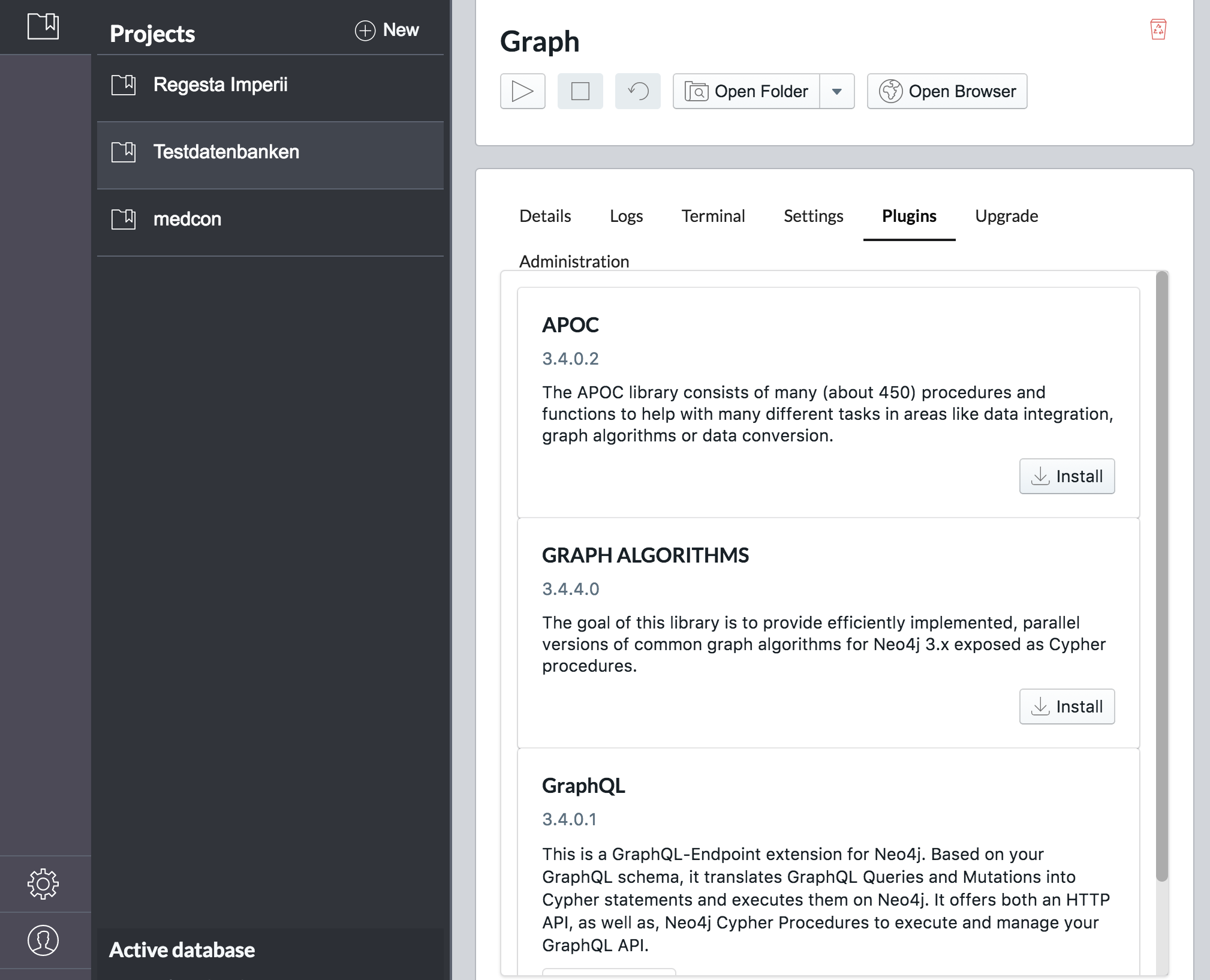
Liste aller Funktionen
Nach dem Neustart der Datenbank stehen die zusätzlichen Funktionen zur Verfügung. Mit folgendem Befehl kann überprüft werden, ob die Apoc-Bibliotheken installiert sind:
CALL dbms.functions()
Wenn eine Liste mit Funktionen ausgegeben wird, war die Installation erfolgreich. Falls nicht, sollte die Datenbank nochmals neu gestartet werden.
Dokumentation aller Funktionen
In der Dokumentation der Apoc-Bibliothek sind die einzelnen Funktionen genauer beschrieben.
apoc.xml.import
Mit dem Befehl apoc.xml.import ist es möglich, einen XML-Text-Dateien 1:1 in die Graphdatenbank einzuspielen. Die Dokumentation findet sich hier.
Beispielbefehl: call apoc.xml.import(“URL”,{relType:’NEXT_WORD’, label:’XmlWord’, filterLeadingWhitespace:true}) yield node return node;
| Kantentyp | Beschreibung |
|---|---|
| :IS_CHILD_OF | Verweis auf eingeschachteltes XML-Element |
| :FIRST_CHILD_OF | Verweis auf das erste untergeordnete Element |
| :NEXT_SIBLING | Verweis auf das nächste XML-Element auf der gleichen Ebene |
| :NEXT | Erzeugt eine lineare Kette durch das gesamte XML-Dokument und gibt so die Serialität des XMLs wieder |
| :NEXT_WORD | Verbindet Wortknoten zu einer Kette von Wortknoten. Wird nur erzeugt, wenn createNextWordRelationships:true gesetzt wird |
(apoc.load.json)
(Dieser Abschnitt befindet sich gerade in Bearbeitung)
Beispiel 1
Import einer geschachtelten JSON-Datei in neo4j
// Themen importieren
WITH 'http://jlu-buster.mni.thm.de/~kuczera/Luhmann/Inhaltsuebersicht_ZKI.json'
AS json_file
// get all of the ID values
CALL apoc.load.json(json_file,"$..id") YIELD value AS result
WITH json_file, result.result AS keys
// for each ID value get all of the children
UNWIND range(0,size(keys)-1) AS i
WITH keys[i] AS parent_key, json_file
WHERE parent_key IS NOT NULL
CALL apoc.load.json(json_file,"$..[?(@.id == '" + toString(parent_key) +"')].children[*]") YIELD value AS children
// create the parents and children and link them up
MERGE (parent:GroupNode {name: parent_key})
WITH parent, children
UNWIND children as child
WITH parent, children, child
WHERE child.id IS NOT NULL
MERGE (childNode:GroupNode {name: child.id})
SET childNode.start_ekin = child.start_ekin, childNode.end_ekin = child.end_ekin, childNode.title = child.title
MERGE (childNode)-[:CHILD_OF]->(parent)
RETURN count(*);
Beispiel 2
Laden der json-Daten der Germania Sacra.
CALL apoc.schema.assert({},{},true) YIELD label, key
RETURN *;
MATCH (n) DETACH DELETE n;
CREATE INDEX ON :Person(GSid);
CREATE INDEX ON :Person(Orden);
CREATE INDEX ON :Kloster(bistum);
CREATE INDEX ON :Amt(bezeichnung);
CREATE INDEX ON :PersonAmt(bezeichnung);
CREATE INDEX ON :Institution(institutionId);
CREATE INDEX ON :Orden(bezeichnung);
CREATE CONSTRAINT ON (p:Person) assert p.id is unique;
CREATE CONSTRAINT ON (k:Kloster) assert k.id is unique;
// Germania Sacra Personendaten importieren
UNWIND range(1,755) as page
CALL apoc.load.json("http://personendatenbank.germania-sacra.de/api/v1.0/person?format=json&id=%2A&limit=100&page=" + page) YIELD value
UNWIND value.records AS r
CREATE (p:Person {GSid: r.person.id,
vorname: r.person.vorname,
vornamenvarianten: r.person.vornamenvarianten,
namenspraefix: r.person.namenspraefix,
familienname: r.person.familienname,
familiennamenvarianten: r.person.familiennamenvarianten,
namenszusatz: r.person.namenszusatz,
herkunftsname: r.person.herkunftsname,
titel: r.person.titel,
orden: r.person.orden,
geburtsdatum: r.person.geburtsdatum,
sterbedatum: r.person.sterbedatum,
belegdaten: r.person.belegdaten,
taetigkeit: r.person.taetigkeit,
gndnummer: r.person.gndnummer,
cerlid: r.person.cerlid,
viaf: r.person.viaf,
verwandtschaften: r.person.verwandtschaften,
anmerkungen: r.person.anmerkungen,
gsId:r.item.gsn.nummer})
WITH r, p
UNWIND r.aemter AS i
CREATE (a:PersonAmt {bezeichnung:i.bezeichnung,
art: i.weltlich,
institution: i.institution,
ort: i.ort,
dioezese: i.dioezese,
gebiet: i.gebiet,
klosterid: i.klosterid,
weihegrad: i.weihegrad,
von: i.von,
bis: i.bis,
latitude: i.latitude,
longitude: i.longitude,
anmerkung: i.anmerkung})
CREATE (p)-[:HAT_AMT]->(a)
RETURN *;
// GND-und VIAF-Nummern auf NULL setzen, wenn nicht vorhanden
MATCH (n:Person)
WHERE n.gndnummer = ""
SET n.gndnummer = NULL;
MATCH (n:Person)
WHERE n.viaf = ""
SET n.viaf = NULL;
Json rekursiv einlesen
// file with json data
WITH 'file:///somedirectory/recursive.json' AS json_file
// get all of the ID values
CALL apoc.load.json(json_file,"$..ID") YIELD value AS result
WITH json_file, result.result AS keys
// for each ID value get all of the children
UNWIND range(0,size(keys)-1) AS i
CALL apoc.load.json(json_file,"$..[?(@.ID == '" + toString(keys[i]) + "')].groups[*].ID") YIELD value AS children
// create the parents and children and link them up
WITH keys[i] AS parent_key, children.result AS children
MERGE (parent:GroupNode {name: parent_key})
WITH parent, children
UNWIND children as child_key
MERGE (child:GroupNode {name: child_key})
MERGE (child)-[:CHILD_OF]->(parent)
RETURN *
Quelle: https://community.neo4j.com/t/import-nodes-from-recursively-structured-json/11704/2
## (neosemantics)
(Dieser Abschnitt befindet sich gerade in Bearbeitung)
Beispiel: Laden eines [Json-Beispiels](https://corpusvitrearum.de/id/about.html) des Projekts [CVMA](https://corpusvitrearum.de/).
~~~cypher
CALL apoc.schema.assert({},{},true) YIELD label, key
RETURN *;
MATCH (n) DETACH DELETE n;
CREATE INDEX ON :Resource(uri);
UNWIND range(1,14) as page
CALL
apoc.load.json("https://corpusvitrearum.de/id/about.json?tx_vocabulary_about[limit]=500&tx_vocabulary_about[page]="
+ page) YIELD value
UNWIND value.`http://www.w3.org/ns/hydra/core#member` AS item
CALL semantics.importRDF(item.`@id`, "JSON-LD") YIELD triplesLoaded
RETURN triplesLoaded;
(json in neo4j laden - der foreach-trick von Michael Hunger)
(Dieser Abschnitt befindet sich gerade in Bearbeitung)
Quelle: lord of the Wiki Rings.
// Iterate over characters
MATCH (r:Character)
// Prepare a SparQL query
WITH 'SELECT *
WHERE{
?item rdfs:label ?name .
filter (?item = wd:' + r.id + ')
filter (lang(?name) = "en" ) .
OPTIONAL{
?item wdt:P21 [rdfs:label ?gender] .
filter (lang(?gender)="en")
}
OPTIONAL{
?item wdt:P27 [rdfs:label ?country] .
filter (lang(?country)="en")
}
OPTIONAL{
?item wdt:P1196 [rdfs:label ?death] .
filter (lang(?death)="en")
}}' AS sparql, r
// make a request to Wikidata
CALL apoc.load.jsonParams(
"https://query.wikidata.org/sparql?query=" +
apoc.text.urlencode(sparql),
{ Accept: "application/sparql-results+json"}, null)
YIELD value
UNWIND value['results']['bindings'] as row
SET r.gender = row['gender']['value'],
r.manner_of_death = row['death']['value']
// Execute FOREACH statement
FOREACH(ignoreme in case when row['country'] is not null then [1] else [] end |
MERGE (c:Country{name:row['country']['value']})
MERGE (r)-[:IN_COUNTRY]->(c))
Quelle von Michael Hunger: https://medium.com/neo4j/5-tips-tricks-for-fast-batched-updates-of-graph-structures-with-neo4j-and-cypher-73c7f693c8cc